What does DIGIT Deployment mean
- Provisioning the kubernetes Cluster in any of the commercial cloud or private state datacenter or NIC
- Setting up the
...
- persistent disk volumes to attach to
...
- DIGIT backbone stateful containers like (Kafka, Elastic Search, ZooKeeper)
- Setting up the PostGres DB
...
- Preparing Deployment configuration using Templates from the InfraOps
- K8s Secrets
- K8s ConfigMaps
...
- Environment variables of each microservices
- Preparing DIGIT Service helm templates to deploy on kubernetes cluster
- Setting up Jenkins Job to build, bake images and deploy the components for the rolling updates.
- Setup Application monitoring, Distributed Tracing, Alert management
High-level sequence of deployment
- Create Kubernetes Cluster
- DB Setup
- Provision Persistant volumes
- Deploy configuration and deployment in the following Services Lists
- Backbone (Redis, ZooKeeper,Kafka, ES-Data, ES-Client, ES-Master)
- Gateway (Zuul, nginx-ingress-controller)
- Core Services
- Business Services
- Municipal services
- Infra services
- Frontend
- Setup CI Jenkins, Docker Registry
- Setup Deployment CI/CD
Prerequisites
- General
- Understanding of VM Instances, LoadBalancers, SecurityGroups/Firewalls, ngnix, DB Instance, Data Volumes.
- Experience of kubernetes, docker, jenkins, helm, Infra-as-code, Terraform
- Clound Cloud Infra - Permission and account to provision the above resources.
- On-premise/private cloud requirements
- Cloud Interface access to provision above infra
- Public cloud requirements
- AWS or Azure account or GCP

Sample Kubernetes Architecture:
...
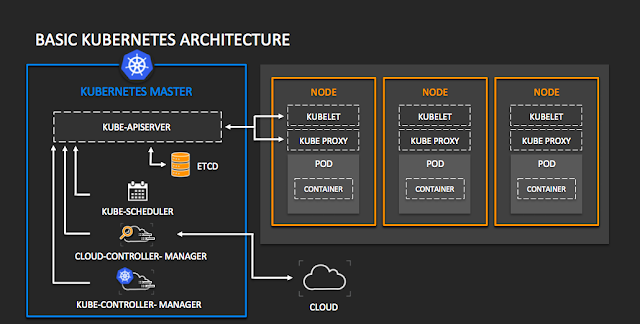
Infrastructure Components
- Basic Requirements (Size, Memory)
- Infrastructure type (Services, DB servers, Storage, etc)
- DB
- Persistant volumes (NFS/iSCSI/SWIFT/etc)
- LoadBalancer or Public IP
- DNS, SSL
- Environments to set up (Development, Production, etc)
- Dev, UAT and Prod
- Services to be used on each Infrastructure type
- Backbone
- eGov Platform Services
- Municipal Services
- Infra Services
- Frontend
Deployment Architecture:
Every code commit is well reviewed and merged to master branch through Pull Requests
Each merge triggers a new CI Pipeline that ensures CodeQuality and CITests before building the artefacts.
Artefact are version controlled and pushed to Artifactory like Nexus. https://repo.egovernments.org
After successful CI, Jenkins bakes the Docker Images with the Latest Artefacts and pushes the newly baked docker image to Docker Registry.
Deployment Pipeline pulls the Image and pushes to the corresponding Env.
Deployment Scripts:
- https://github.com/egovernments/eGov-infraOpsPython based OR https://github.com/egovernments/Train-InfraOps
Golang base Deployment script that reads the value from the
Jinja 2helm charts template and deploys into the cluster.
Each env will have one master Template that will have the definition of all the services to be deployed, their
dependanciesdependencies like Config, Env, Secrets, DB Credentials, Persistent Volumes, Manifest, Routing Rules, etc..


Deployment Configurations
Let's Get Started - Hands on
- Create Kubernetes Cluster
- Local Development K8S Cluster: Use development support environment for creating Kubernetes Cluster. Eg : Minikube.
- Cloud Native K8S Cluster Services: Use Cloud Services to create Kubernetes Cluster. Eg : AWS EKS Service.
- On-Premise K8S Cluster: Create your own Kubernetes Cluster with the help of master and worker nodes.
- K8s Cluster Requirement
- Cloud native kubernetes engine like AKS, or EKS or GKE from AWS or Azure or GCP respectively
- 6 k8s Nodes- with each 16GB RAM and 4 vCore CPUs
- On-Prem/Data Center or custom
- 1 Bastion- 2GB RAM 1vCore CPU
- 3 k8s Master- 2 GB RAM 2 vCore CPU
- 4- 6 k8s Nodes with each 16GB RAM and 4 vCore CPU
- Cloud native kubernetes engine like AKS, or EKS or GKE from AWS or Azure or GCP respectively
Kubernetes Cluster Provisioning
- Managed Kubernetes Engine:
Choose your cloud provider (Azure, AWS, GCP or your private)
Choose to go with the cloud provider specific Kubernetes Managed Engine like AKS, EKS, GKE.
Follow the Cloud provider specific instruction to create a Kubernetes Cluster (stable version 1.11 and Beyond) with 5 to 6 worker nodes with 16GB RAM and 4 vCore CPU (m4.xlarge)
PostGres DB (Incase of AWS, Azure, GCP use the RDS) and have the DB server and the DB Credentials details.
Provision the disk volumes for Kafka, ES-Cluster and ZooKeeper as per the below baselines and gather the volume ID details.
Install Kubectl on DevOps local machine to interact with the cluster, setup kubeconfig with the allowed user credentials.
Sample volumes to be provisioned

2. Private Cloud - Manually setup Kubernetes Cluster:
- Create a VPC or Virtual Private Network with multi availability zones
Provision the Linux VMs with any Container Optimised OS (CoreOS, RHEL, Ubuntu, Debian, etc) within the VPC Subnet.
Provision 1 Bastion Host that acts as proxy server to Kubernetes cluster Nodes.
3 Master Nodes with 4 GB RAM 2 vCore CPU
6 worker nodes with 16GB RAM and 4 vCore CPU
PostGres DB (Linux VM)
Provision the disk volumes for Kafka, ES-Cluster and ZooKeeper as per the below baselines and gather the volume ID details.
- Create LoadBalancer or Ingress to talk to Kube API server that routes the external traffic to the services deployed on cluster.
- Setup AuthN & AuthZ.
Install Kubectl on DevOps local machine to interact with the cluster, setup kubeconfig with the allowed user credentials
Useful Step-By-Step Links:
- Installing the Client Tools
- Provisioning Compute Resources
- Provisioning the CA and Generating TLS Certificates
- Generating Kubernetes Configuration Files for Authentication
- Generating the Data Encryption Config and Key
- Bootstrapping the etcd Cluster
- Bootstrapping the Kubernetes Control Plane
- Bootstrapping the Kubernetes Worker Nodes
- Configuring kubectl for Remote Access
- Provisioning Pod Network Routes
- DB Setup
- Use managed RDS Service with PostGres if you are using AWS, Azure or GCP
- Else provision a VM with PostGres DB and attach external volumes
- Keep data on volumes, Create persistant volums
- In case of Kubernetes volume, when a pod is deleted, all the data is lost too.
- Thus, we use Persistent Volumes, which will keep the data even if a pod is spawned.
- It stores the data on our local storage.
- eg: There is a Persistent Volume for elastic searchl. So, if the data inside the database will increase, the size of the local storage will also be needed to be increased.
- Thus, it is a best practice to keep database outside the kubernetes cluster.
- Setup Registry for build libraries & docker images
- Create central container registry such as AWS EKS or Gitlab Registry or DockerHub or Artifactory.
- CI Tools will push the container image to the central container registry.
- Here we are using Nexus, DockerHub as shared repositories
- Create Production ready Application Services Lists
- Backbone
- Infra: Elastic Search HA Cluster, Kafka HA Cluster, Zookeeper HA Cluster, Redis, Kafka Connect, Kibana, ES Curator
- Business: Elastic Search HA Cluster, Kafka HA Cluster, Zookeeper HA Cluster, Kafka Connect, Kibana, ES Curator
- Gateway
- ngnix ingress
- zuul


- eGov Platform Services
- egovio/employee
- egovio/citizen
- egovio/user-otp
- egovio/egov-accesscontrol
- egovio/egov-common-masters
- egovio/egov-filestore
- egovio/egov-idgen
- egovio/egov-indexer
- egovio/egov-localization
- egovio/egov-persister
- egovio/egov-searcher
- egovio/rainmaker-pgr
- egovio/egov-notification-sms
- egovio/egov-otp
- egovio/egov-user
- egovio/hr-masters-v2
- egovio/hr-employee-v2
- egovio/report
- egovio/tenant
- egovio/egov-mdms-service
- Business Services
- billing-service
- collection-services
- dashboard-analytics
- dashboard-ingest
- egf-account-details-consumer
- egf-instrument
- egf-masters
- egf-voucher-indexer
- egov-apportion-service
- egov-hrms
- finance-collections-voucher-consumer
- whatsapp-webhook
- Municipal Services
- Public Grievance Redressal System
- Property Tax System
- Trade License System
- Accounting System
- Water & Sewerage Management (ERP)
- Dashboards
- Fire No Objection Certificate (NoC)
- Infra Services
- Fluentd,
- Kibana
- Telemetry
- Logging
- Frontend
- Web Citizen, Employee, etc.
- Backbone
- Setup CI
- Create and configure shared repository for Continuous Push, Commit, etc.
- Setup CI like Jenkins and create the Job that creates a pipeline from the JenkinsFile.
- Platform services can be referred and forked from https://github.com/egovernments/core-services
- Install and configure continuous deployment tools for automatic build and test.
- Builds are created from the Build management scripts, written inside InfraOps GitHub Repo (Private).
- With every deployment, a new container is deployed which saves the overhead of doing manual configurations.
- We can run pre-built and configured components in containers as a part of every release.
- We provide all the kubernetes cluster configurations through .yaml files, which is usually called as the desired state of the cluster.
- Kubernetes offers autoscaling of workload based on CPU utilisation and memory consumption.
- Kubernetes allows vertical scaling-increasing the no. Of CPU’s for pods and horizontal scaling-increasing the no. of pods
- Upgrading the platform/installation/services
- We are using Jenkins/Spinnaker as CI/CD Tool

Cluster/Service Monitoring
- Monitoring
- Prometheus / CloudWatch for node monitoring
- Prometheus for pod level monitoring
...
- Jaeger for distributed tracing
- Traces are tagged with correlation-id



Multi-environment Cluster Orchestration and Management
