Understanding DIGIT Infra, Services Integration & deployment
- Gajendran C (Unlicensed)
- Omkar Ghatpande
- Nithin DV (Unlicensed)
Deploying eGov services means that the respective services can be developed, packaged as docker containers and deployed into kubernetes Cluster by simply updating the "master deployment config File per environment" which is derived from the jina2 templates. This allows all the environments specific overrides, credentials and values.
From Code to Deploy flow
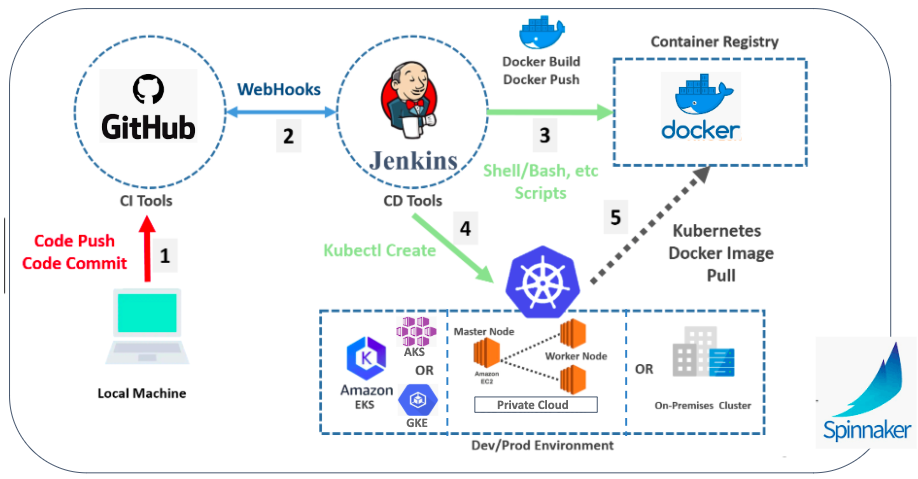
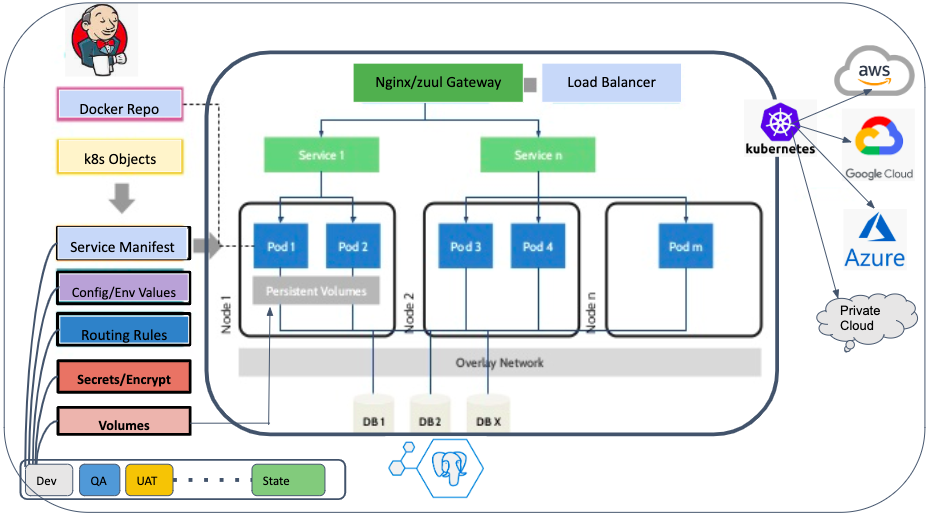
Instructions
1. Structure of a Sample service to be maintained in the Git Repo:
Ifa Micro Service or a Web/Mobile module is being developed it needs to have certain following key elements configured and checked into the Git Repo in the following structure.- Git Repo
Micro Services: https://github.com/digit-egov/core-servicesWeb: https://github.com/digit-egov/frontendbusiness-services: https://github.com/digit-egov/business-services- business-services: https://github.com/digit-egov/municipal-services
MDMS: https://github.com/digit-egov/playground-mdms-data
- Each service with have its 'Dockerfile' defining the base image, port and the dependencies, .jar or .war file to copy and start the service or it can refer to a common dockerfile.
If a service requires a DB migration it needs to be added in the following hierarchy along with the migration scripts and the seed files
- Git Repo

2. Deployment templates in the Git Repo:
- https://github.com/egovernments/eGov-infraOps/ OR https://github.com/egovernments/Train-InfraOps
- Jinja 2 templates are created for all kubernetes manifests.
- Jenkins jobs are used to deploy to cluster using these templates.
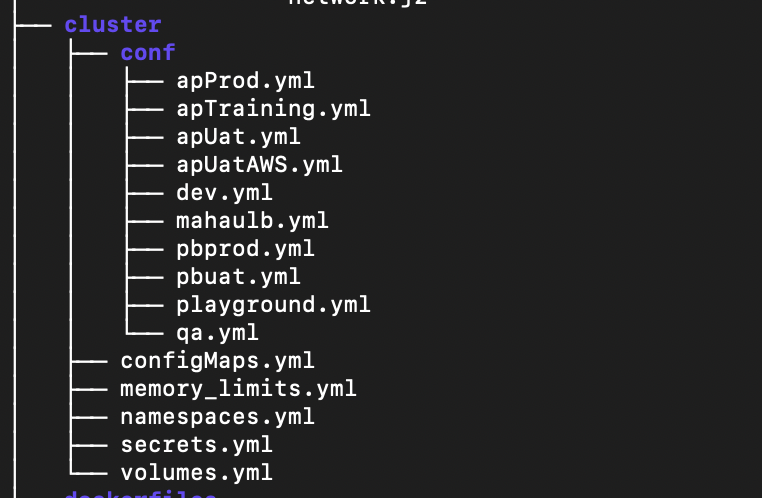 .
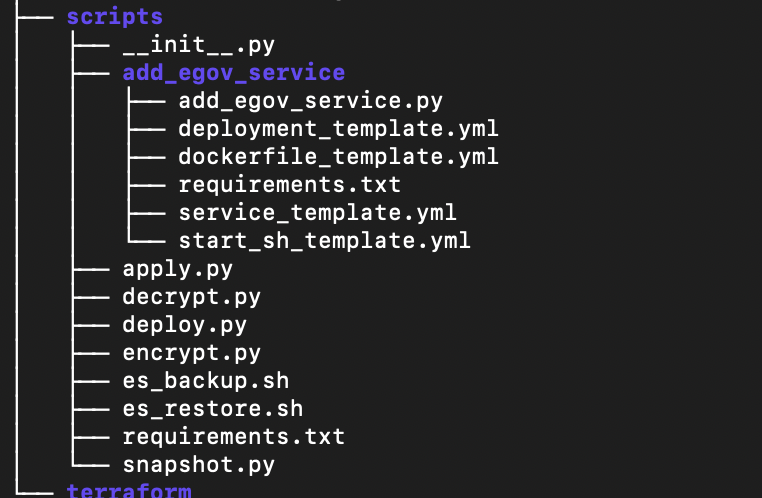
. 
Environment Configuration (Dev.yml, QA.yml, etc...)
Environment configuration is used to configure the services which shall be deployed on an environment. It serves
- List of services and their properties
- Global configuration parameters, ex: db settings
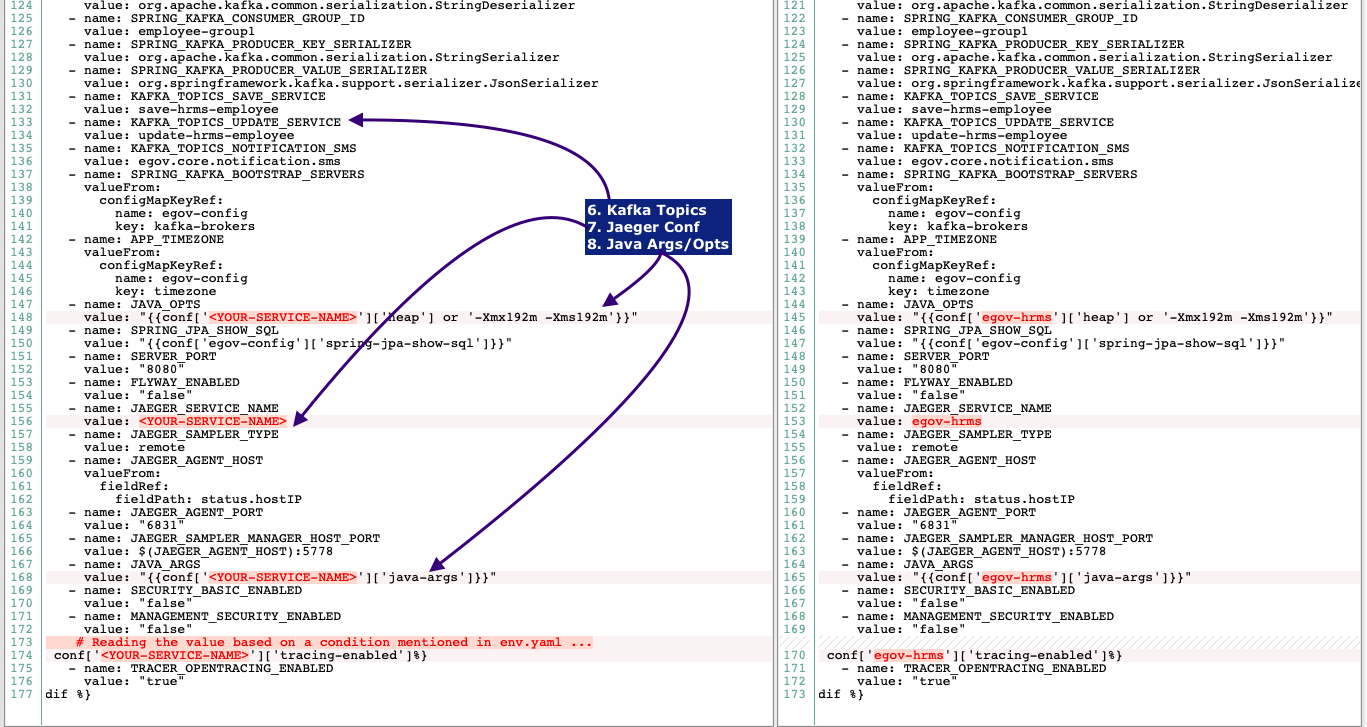
- Kafka topics and their partition/replication count
- Endpoints that needs to be whitelisted
- Encrypted Secrets # Kubernetes Secrets are used to store and serve secrets to various services
An example configuration can be found at InfraOps repo
Secrets.yml
Secrets are provided to various services through Kubernetes Secrets. These secrets are AES encrypted using a salt and configured on environment configuration manifests.
To encrypt
$ python encrypt.py <secret text>
To decrypt
$ python decrypt.py <secret text> | base64 -d
NOTE: Salt needs to be available as environment variable called "EGOV_SECRET_PASSCODE" which is also added in Jenkins Credentials to decrypt while deploying a service.A separate secrets.yml is maintained to push the required secrets to environments.
Volumes.yml
Some services needs persistent storage to store the data. Volumes are configured through volumes.yml and applied whenever required on the environments.
Kubernetes supports many persistent storage volumes and can be configured in volumes.yml.
Namespaces.yml
eGov cluster consists of 4 major kubernetes namespaces.
- backbone
- egov
- es-cluster
- logging
backbone
Backbone namespace consists of
- kafka: Kafka is used extensively throughout eGov services platform. Kafka manifest consists of a Service definition and Statefulset definition. These manifests also support data volumes which are needed to persist data. Replicas of kafka nodes can be controlled by the environment manifests.
- zookeeper: Zookeeper manifest contains a service spec and Statefulset spec. Number of zookeeper replicas can be controlled through environment manifests.
- Redis: Redis is used to store app session data. Redis manifests contains a service definition and Statefulset definition.
- kafka-create-topic: By default, kafka creates topic (with 1 replication/ 1 partition) if does not exist when the first message is pushed to a topic by a producer. However, it does not create the topic with increased number of replication and partition based on the cluster setup. Hence, kafka-create-topic is used to create kafka topics. Topic names and their respective replication/partitions are provided through environment manifests. Kafka-create-topic is a Kubernetes Job definition which should be run by kubectl apply command.
egov
eGov services mainly follow the following pattern.
- Kubernetes Service definition
- Kubernetes Deployment definition
- Init containers for environment specific db migration if required
- Init containers for flyway db migration if required
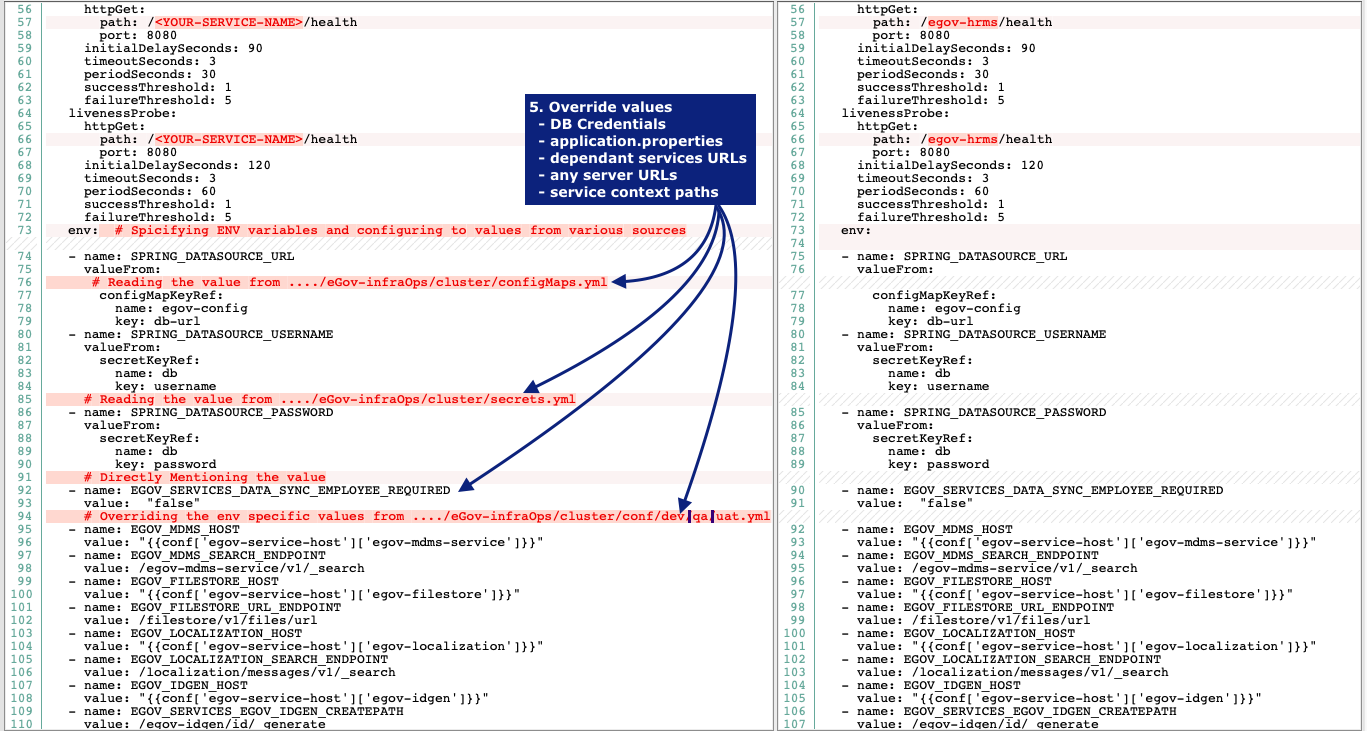
- Service configuration parameters in the form of environment variables
- System resource limits
Note: DB migrations may not be needed for web projects.
es-cluster
eGov uses Elasticsearch for storing some of persistent data. It is also used to aggregate all pods logs. es-cluster consists of
- es-client: Client ES service which all eGov services connects to
- es-data: Data node which stores all data. Number of replicas can be controlled through environment manifests.
- es-master: Master node to manage the es-cluster
- Kibana: Kibana visualization for both business data and logs
logging
eGov uses fluentbit to aggregate all logs and push to elasticsearch. Fluentbit runs as Daemonset on all minions which collects logs from all pods.
A Kubernetes cronjob called delete-old-logs-in-es is created to cleanup all pods logs from elasticsearch cluster regularly. Number of days to keep the logs can be controlled through environment manifests.
Addition to cronjob, logrotate cron job will be running on all minions which can rotate the logs including system logs. Frequency and number of days to rotate the logs can be controlled through environment manifests.
other
There are two more namespaces which can be deployed based on the need.
- Playground namespace consists of a playground pod which can be used to execute commands on an environment.
- Monitoring namespace used to configure monitoring solution for the cluster environment. Currently it is in alpha stage.
- kafka: Kafka is used extensively throughout eGov services platform. Kafka manifest consists of a Service definition and Statefulset definition. These manifests also support data volumes which are needed to persist data. Replicas of kafka nodes can be controlled by the environment manifests.
Add service manifests
cluster/app/egov/<module>/<service-name>.yml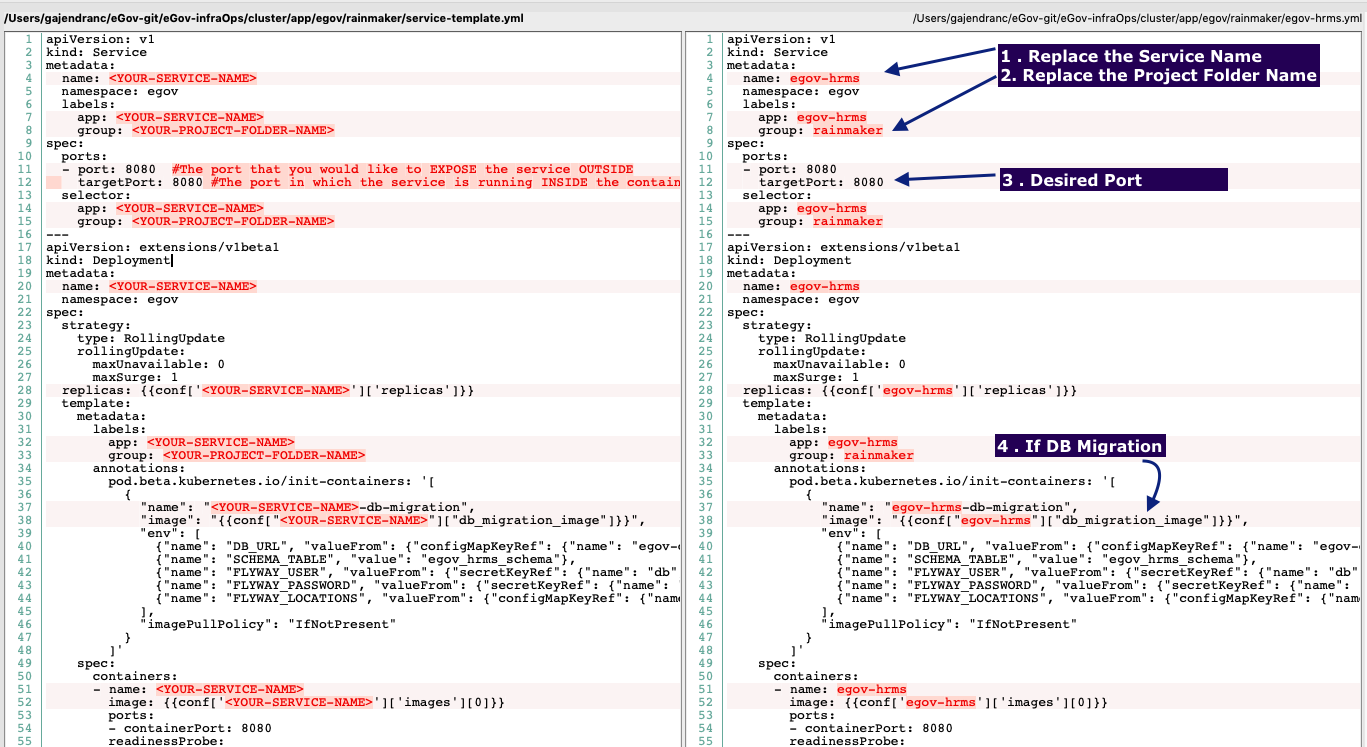
Add configMap if any
cluster/conf/configMaps.yml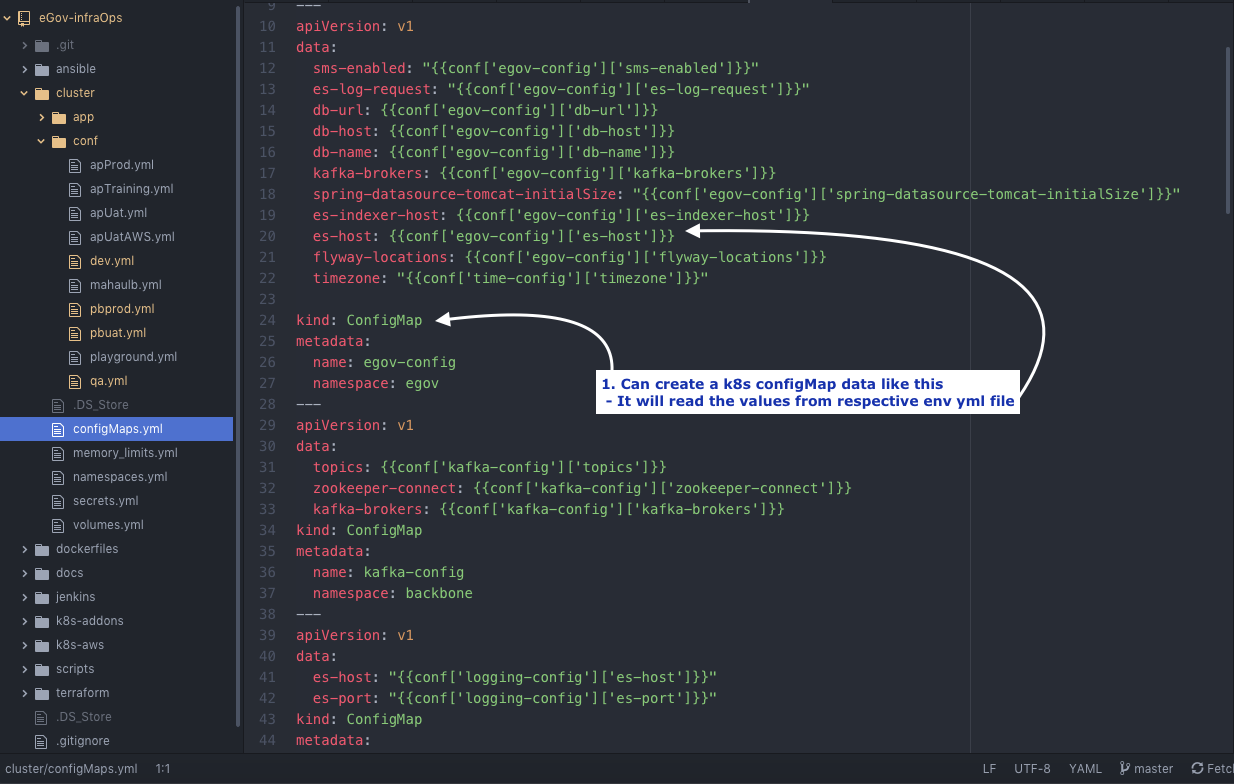
Add encrypted credentials if any
cluster/conf/secrets.yml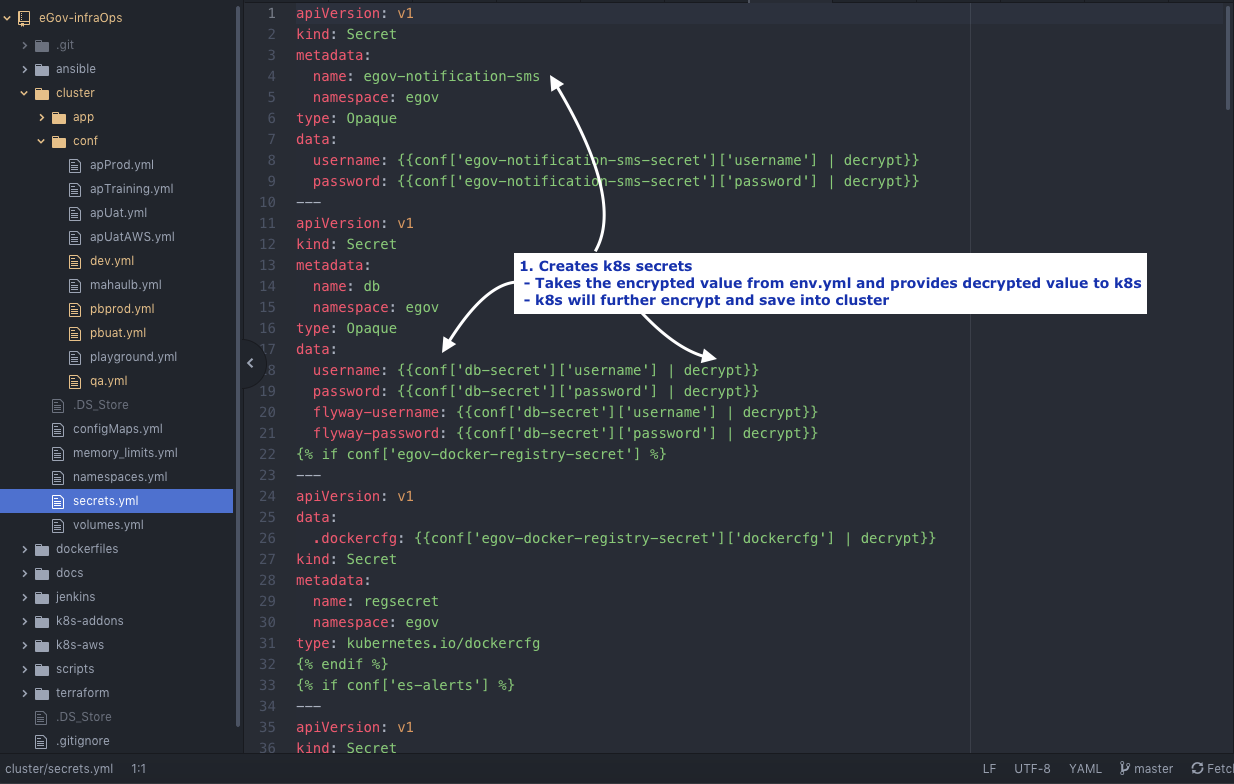
Provision the volumes and mention the volume conf to pick the volume ID based on the ENV credentials if any
cluster/volumes.yml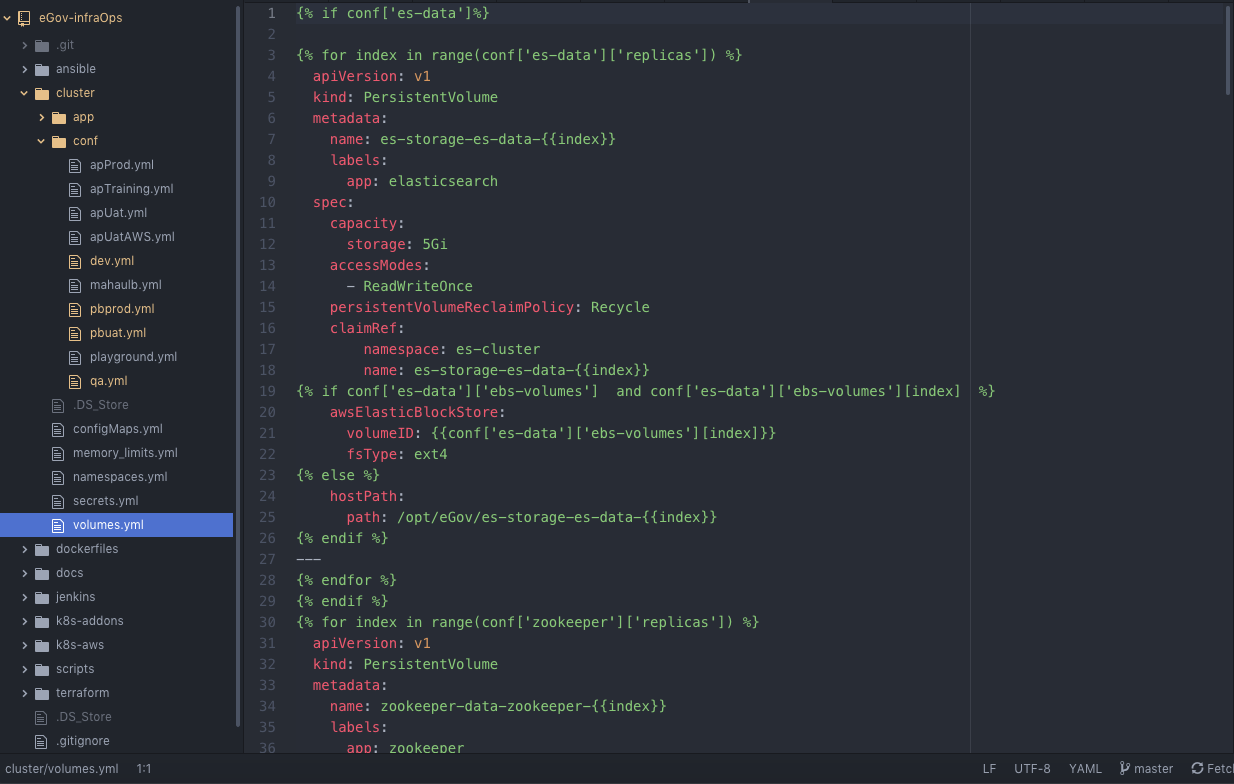
Add the conf to env
cluster/conf/dev.yaml | qa.yml | uat.yml | prod.yml | state.yaml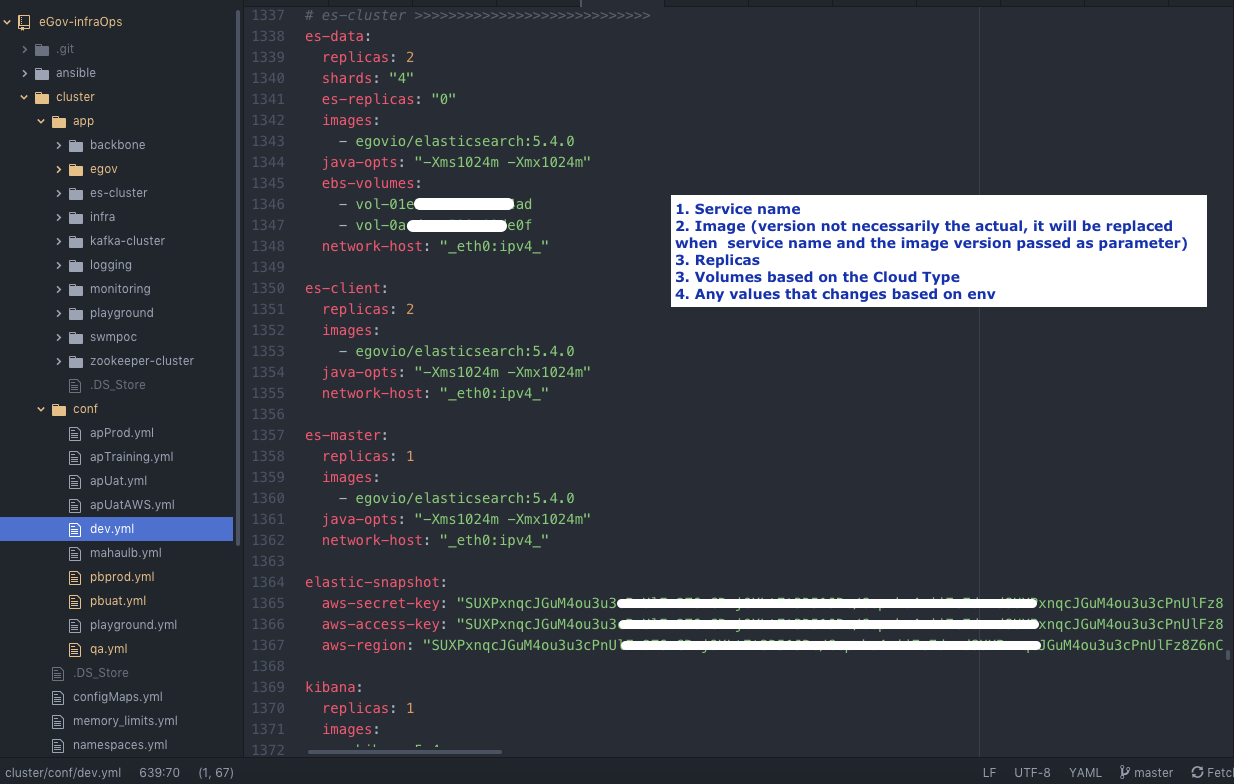
Add ZUUL Routes
cluster/app/egov/gateway/zuul.yml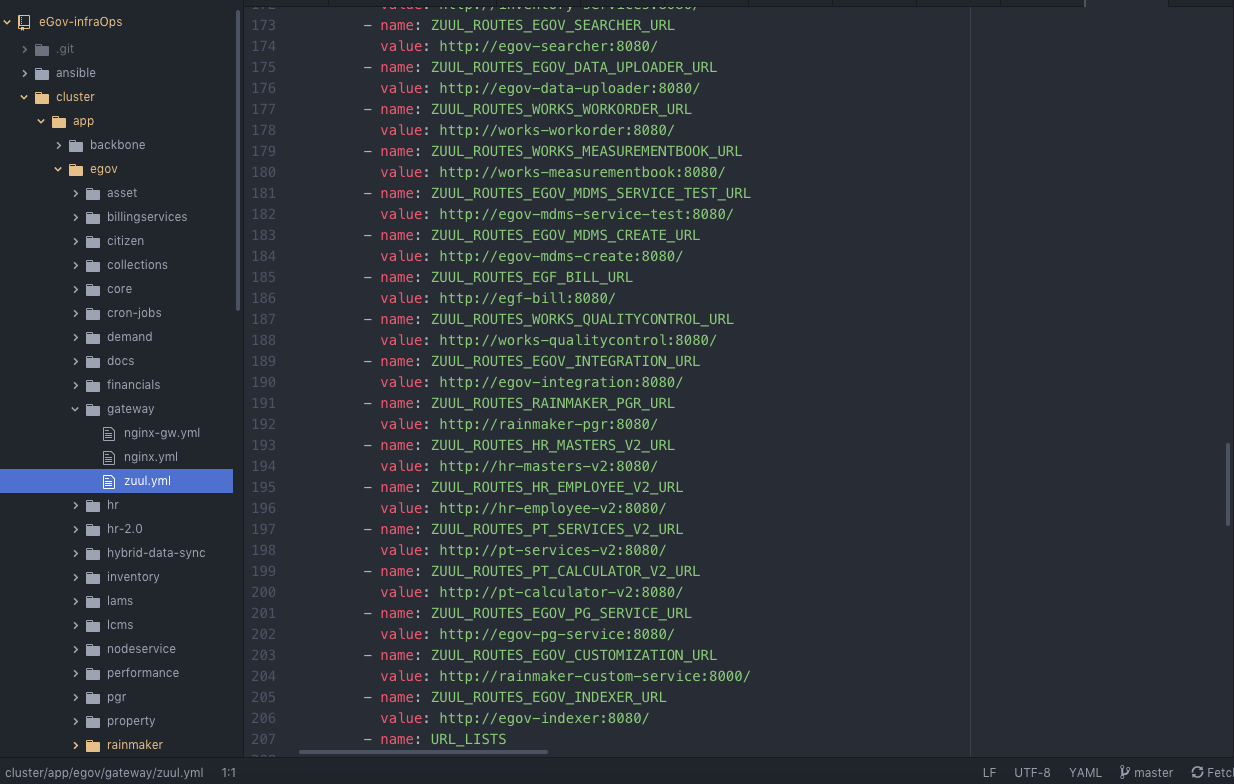
CI Setup - Configuring Build Jobs - Jenkins
- https://github.com/egovernments/eGov-infraOps/tree/master/jenkins
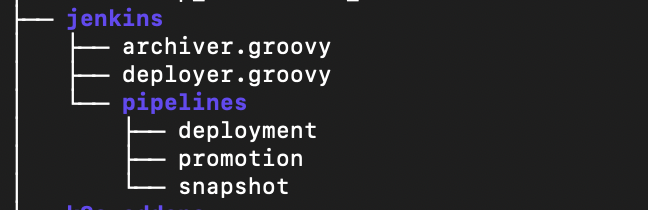
CI Job Structure
- https://github.com/digit-egov/core-services/blob/master/build/build-config.yml
- Add build config and run the Job Builder job to create the pipelines.
- https://builds.egovernments.org/job/Job-Builder/ . (Incase of partner, it is their jenkins)
Build Flow
- During build, Groovy script (Jenkinsfile) from root of the repo is called by Jenkins
- Script will force run the build on slave server Build has five stages
1. Build :
- Script checks for build.wkflo existence in repo for this service. If exists, follow the workflow defined in it.
- Else runs default build instructions from build.sh
- build.sh brings up CI container which has necessary pre-installed software and run maven build inside the container.
2. Archive Results:
- Jenkins then archives the generated artifacts within Jenkins
3. Build Docker Image
- Groovy script Jenkinsfile uses the Dockerfile found in /<service_name> to build the docker image.
- These images are tagged as egovio/<service_name>:<Jenkins_Job_ID>-<Branch_name>-<Git_Commit_Hash_of_the_workdir>
4. Publish Docker Image
- Script then pushes all images found in the host to docker registry.
Deploy a service
- Deploy Image - Continuous Delivery Pipeline.
- Each deploy job name should have the naming convention of deploy-to-
- Job takes two parameters <service name> and <tag> as inputs
- Each job is a pipeline job with the following configurations
- Name: deploy-to-
- Pipeline Definition: Pipeline script from SCM
- Repository:
- ScriptPath: jenkins/pipelines/deployment
- Deployment Flow
- Jenkins takes service name and docker tag from the user as input
- deployer.groovy sets up kubernetes environment from Jenkins credentials. Following credentials should be available to the script
- -kube-config
- -aws-secret-access-key, -aws-region, -aws-access-key in case of EKS with auth
- egov_secret_passcode #Which was used to encrypt passwords in environment manifests
- Groovy script then executes python script apply.py with the arguments env, service, docker_image:tag, docker_db_migration_image:tag
- apply.py reads all arguments and renders following yaml's
- namespaces.yml
- configMaps.yml
- secrets.yml
- volumes.yml
- <service_name>.yml
Note: apply.py uses Jinja2 to parse all environment specific variables from git:eGov-infraOps/cluster/conf/ - apply.py executes "kubectl apply" using the parsed yaml's and prints STDOUT or STDERR.
Related articles